송년 기념으로 가볍게 해 보는 실험
흔히들 개발을 할 때 언급을 되는 것이 “make같은 빌드 프로세스의 작업은 쓰레드 수만큼”이다. 요즘 발달한 CPU성능, 그리고 정교해진 커널 동작을 보면, 어쩌면 쓰레드 초과로 잡는 게 더 자원을 긁어낼 수 있지 않을까? 같은 의문이 들기 마련이다. 현대 개발 환경에서도 유의미한지 가벼운 마음으로 알아보자.
환경
- RAM 64GB, Samsung DDR4 3200MHz
- CPU AMD Ryzen 5 5600X, 4.65 GHz
- B550M Pro4, ASRock
- 하이퍼쓰레딩 사용 기준 논리코어로 12쓰레드 산정
소스
- SSH-Chatter, Commit
e2faa51소스(약 53000줄의 경량 게시판)
정석적인 쓰레드 수대로 했을 때
real 0m3.705s
user 0m18.137s
sys 0m0.775s
쓰레드 수의 1.5배
real 0m3.686s
user 0m18.231s
sys 0m0.748s
쓰레드 수의 2배
real 0m3.606s
user 0m17.806s
sys 0m0.787s
쓰레드 수의 2.5배
real 0m3.551s
user 0m17.483s
sys 0m0.757s
쓰레드 수의 3배
real 0m3.755s
user 0m17.360s
sys 0m0.668s
결과 해석
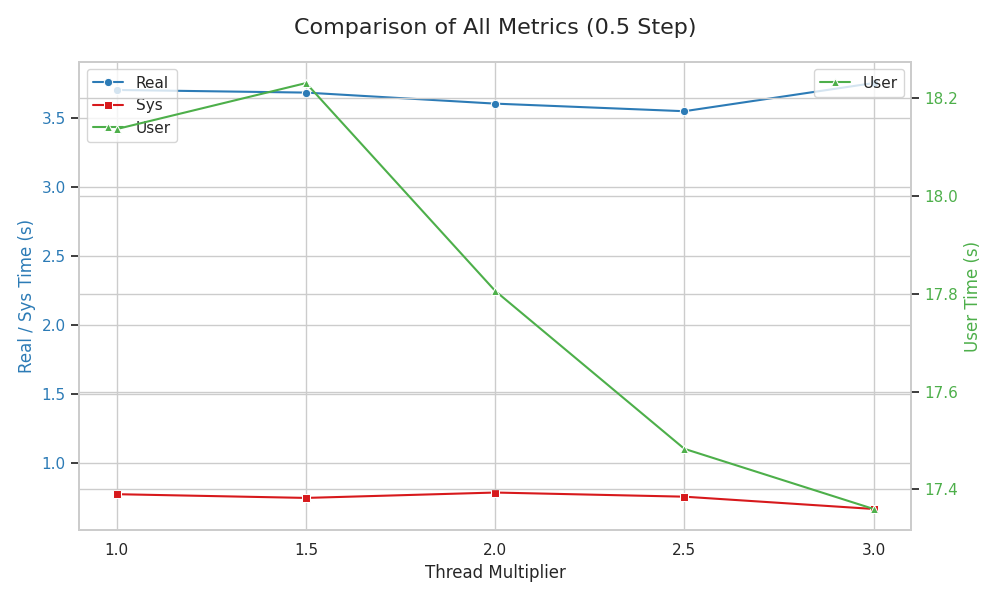
여기서 안내하지만 시스템에 따라 다를 수 있다 결과는 너무나도 충격적이다. 하드웨어의 쓰레드 수의 2.5배가 될 때까지 컴파일 시간은 계속 줄어들었다.
CS 전공자가 아닌 사람들 입장에선 당연한 상식이 머릿속에서 깨지면서 정신이 아득해질지도 모른다. 물론 필자도 CS가 아닌 파생형 전공을 한 사람이기 때문에 말도 안 된다고 생각한 예측이 맞아 들어가는 시나리오가 존재한다는 것을 섣불리 믿기 어렵다.
그렇다면 리눅스 커널 모듈 코드로도 한번 해 보자. 필자의 노트북 튜닝 역작(?) LapUtil을 한번 빌드해 보자.(커밋 26237b0)
정석적인 쓰레드 수
real 0m1.076s
user 0m1.031s
sys 0m0.198s
쓰레드 수의 1.5배
real 0m1.011s
user 0m1.083s
sys 0m0.142s
쓰레드 수의 2배
real 0m1.034s
user 0m1.065s
sys 0m0.177s
결과 해석
아니…어처구니가 없다. 이게 코미디지 다른게 코미딘가? 솔직히 이건 당혹스러움 이상으로 수치심이 들지도 모른다.
여기서도 적더도 쓰레드 수의 1.5배에서 스윗 스팟이고, 2배부터 병목이 생겼지만 여전히 정석보다 빠르다. Windows, Linux와 같은 운영체제, 그리고 현대 컴퓨터과학의 승리인가? 여러모로 마음이 복잡할 수밖에 없다.
추론
리눅스 커널 뿐만 아니라 윈도우 등의 커널도 상당한 수준의 저수준 최적화로 작업을 재배치하는 것으로 알려져 있다. 즉 우리가 집어넣은 대로만 돌아가는 바보 기계가 아니라는 것이다… 어찌저찌 파이프라인 사이사이에 집어넣다 보면 들어가는 구멍이 있는 듯하다. 아마 쑤셔넣었겠지. 정석이든 아니든간에 추가적인 컴파일 시간 최적화가 가능하다. 물론 프로그램의 유형과 규모에 따라 쑤셔넣을 수 있는 정도가 다르지만.
윈도우는 사용하는 기기가 없어서 테스트하지 못하였으나 아마 유사한 경향을 보일 것으로 추정된다.
대체 왜냐?
현대 CPU는 빠르다. 말도 안 되게 최적화되어있고 클럭이 4GHz는 훌쩍 넘는다. 더구나 최신 CPU는 마의 5GHz 따위는 가볍게 무시하고 말도 안 되는 고클럭을 사용한다.
그런 현대 CPU는 지금 들어온 작업을 빠르게 처리하고 유휴상태로 들어간다. 그럼 그 동안은 코어는 놀고 있는 것이다. 대학생한테 하루를 주고 피타고라스 정리를 이용한 중학교 수학 문제 모음들을 쥐어 주면, 수능 성적과 학벌 모두 무관하게 시간이 남는 경우가 많을 것이다. 그럼 대학생은 남는 시간동안 별 일이 없으면 앉아서 쉬고 있는 것이다.
그런데, 피타고라스 정리를 이용한 문제 모음들을 1000개 정도 줘 보자. 전보단 시간을 빡빡하게, 한 문제를 풀고 다음 문제를 풀게 될 것이다.
이것이 파이프라인을 까맣게 칠해버려서 작업으로 가득 채우는 셈인 것이다.
컨텍스트 스위칭? 치타는 웃고 있다….
옛날 운영체제와 달리 요즘 커널들의 컨텍스트 스위칭은 전환 속도가 최적화되어 있다. 즉 작업 전환이 무서워서 CPU를 덜 돌릴 바에는 빠른 현대 OS에게 작업을 가득 던져 주는 편이 낫다. 그렇게 복잡한 작업이 아니면…넉넉하게 던져 보자. 1.5배 던져도 웬만해선 괜찮을 거다.
결론
세상은 때론 여러분의 예상보다 냉혹하다. 불변하는 듯했던, 그렇지만 약간은 구시대적이고 주먹구구식인 make -j$(nproc)이 대체로 합리적으로 컴파일 시간을 줄여주지만, 어째선지 최선이 아닌 것이다..
세계 최고의 석학들이 다 믿고 쓰니까 실험조차 해 보지 말자고 생각한 나를 반성한다.
앞으로는 별로 어렵지 않은 것 같으면 직접 상황을 실험해 보고 다시 한번 고민해 봐야겠다.
P.S) 필자는 전문성이 부족하고 어딘가 맛이 간 듯한 삼류 코딩을 한다. 다시 한 번 말하지만 이 실험의 정확도는 낮다.