해킹의 종류는 여러가지
보통 해킹이라고 하면 어나니머스와 같은 사이버 범죄집단을 생각하는 경우가 많다. 그러나 화이트해킹, 블랙해킹, 정보보호, 어딘가 불쾌한 어나니머스 로고, 자신감 넘치는 체크무늬 남방의 괴짜… 실제로 리눅스의 이미지에 그러한 집단들이 많은 영향을 미쳤다. 인정하고 싶지는 않지만 그런 괴짜들이 빠지면 리눅스 데스크톱의 존립이 휘청일 지경이다.
그러한 것들만이 해킹은 아닐 뿐더러, 리눅스 해킹의 영역도 그게 다가 아니다.
실제로 용도에 맞게 범용 리눅스 커널을 특화해서 뜯어고치거나, 개인적인 용도로 튜닝하는 것도 해킹이라고 부른다. 이번에 우리가 다룰 것도 그런 보안과 별 관련도 없고, 너드, 긱 문화와도 별다른 상관이 없는 시스템 해킹의 영역이다. 손쉬운 튜닝으로 스팀 게임에서 핑이 튀지 않게 방지해 보자. 아마 스팀 덱에서도 잘하면 이식이 될 것이다.
여기서 “비전공자”라고 하는 건, C 기본 문법과 리눅스 커널 빌드/설치를 직접 해본 적은 있는 사람 정도를 상정한다. CS 전공이 아니어도 “각오하고” 따라갈 수 있는 수준이라고 이해하면 된다.
리눅스 커널을 수정해 보자
많은 경우, 리눅스 커널을 수정하는 것은 아주 어려운 일이라고 생각한다. 어떤 파트에 있어서는 확실히 그러하다. 그러나 어떠한 파트에선 그렇지 않다. 이번에 다뤄볼 것은 네트워크 핑이 팍 튀어버리는 지터를 잡는 가벼운 커널 해킹이다.
핑이 팍 튈 때, VoIP 등의 거창한 상황을 가정하지 않아도 LAN에서 뚝 끊어지는 느낌이 있을 수밖에 없다. 이럴 때는 빠르다 튀었다 하는 네트워크 응답보다는 적당한 속도로 지터 없이 응답하는 것이 낫다. 여기서는 “완전한 최적화”보다는 “지터를 줄이는 방향으로 라우팅 경로 선택을 살짝 손대는 것”을 목표로 한다.
문제 설정: 지터와 멀티패스 라우팅
리눅스 커널은 ECMP(동일 비용 멀티패스) 라우팅이 가능하다. 즉, 동일한 비용을 가진 여러 경로가 있을 때, 해시 기반으로 적당히 분산해서 트래픽을 보낸다. 이때 각 경로의 품질(지연, 지터, 실제 처리량)은 동일하지 않을 수 있다.
- 어떤 경로는 RTT가 안정적인 대신 약간 느릴 수 있다.
- 어떤 경로는 RTT 평균은 빠른데, 순간적으로 튀는 구간이 많을 수 있다.
게이밍, 스트리밍, 실시간 상호작용에서는 평균 속도보다 안정성(지터) 이 더 체감된다. 그렇다면 “지터와 부하에 대한 지표를 경로마다 추적해서, 그걸 점수(score)로 만들어 ECMP 선택 로직에 살짝 개입”하면 어떨까?
알고리즘 수립
아이디어는 단순하다.
- 커널이 실제로 패킷을 전송할 때마다, 사용한
dst_entry에 경로별 메트릭을 기록한다. - 이 메트릭을 지수이동평균(EMA)로 누적해서 “부드럽게” 추적한다.
- 멀티패스 라우팅에서 nexthop을 고를 때, 이 메트릭을 조합한 점수(score) 를 참고해서 기존 해시 기반 선택에 약간의 편향을 준다.
개념 정리
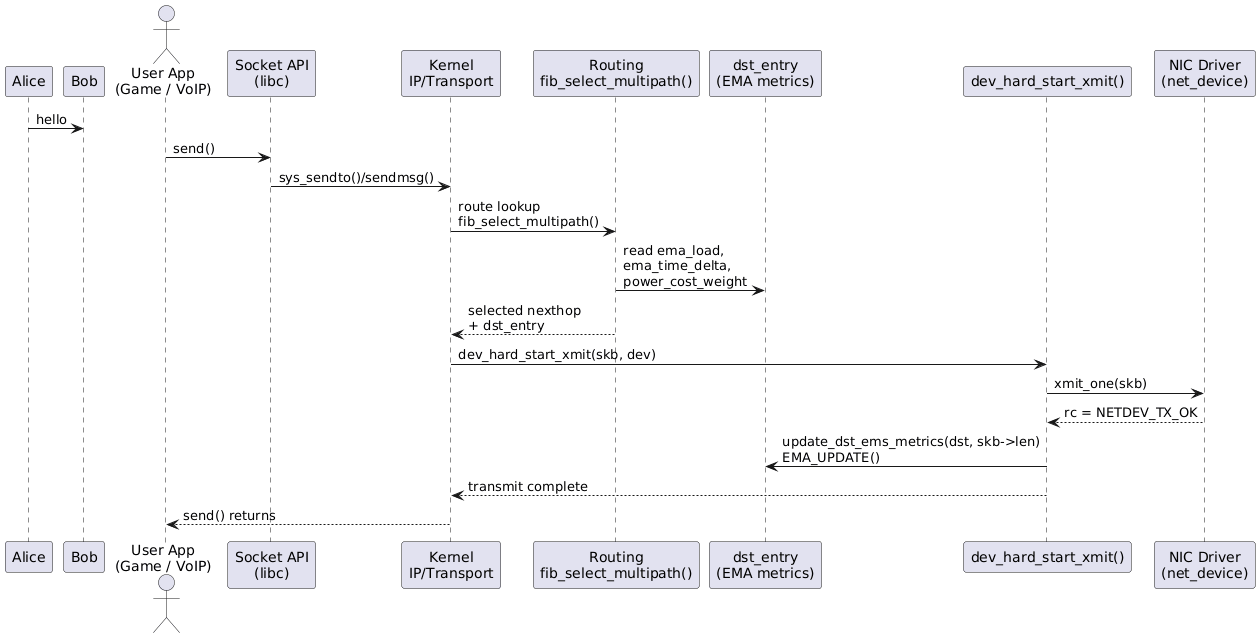
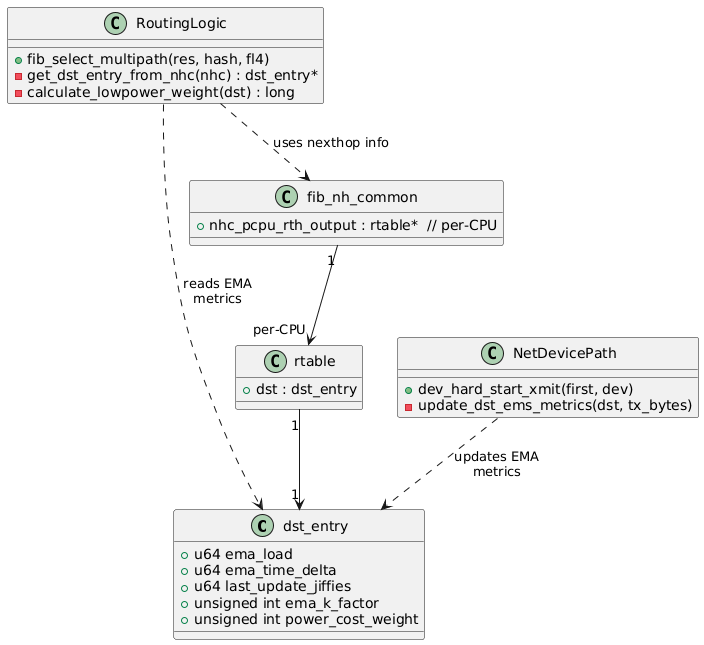
-
라우팅 레벨에서 할 일
- rtable/rt6_info 등
dst_entry기반의 데이터 구조에 메트릭을 붙인다. - 멀티패스 선택 함수(
fib_select_multipath, IPv6의 경우 route scoring)에 메트릭에서 나온 점수를 반영한다.
- rtable/rt6_info 등
-
메트릭 설계
여기서는 “값이 크면 무조건 나쁘다/좋다” 같은 강한 의미를 주기보다는,
경로 상태를 대략 숫자로 표현해서, 그 숫자를 이용해 점수를 만들기 위한 재료라는 느낌으로 보면 된다.ema_load: 단위 시간당 전송 바이트 수를 EMA로 누적한 값
-> “이 경로가 어느 정도 활동을 하고 있는지”를 대략 나타낸다.ema_time_delta: 현재 부하와 EMA 부하의 차이를 EMA로 누적한 값
-> “최근에 어느 정도 변화가 있었는지(변동성)”를 나타낸다.power_cost_weight: 이 링크에 대한 비용/선호도 계수
-> 위 두 값을 어떻게 반영할지 조절하는 노브 역할을 한다.
(지금 글에서의 실험은 모든 경로에 같은 값을 줬고, 환경에 따라 다르게 줄 수도 있다.)
실제로는
ema_load,ema_time_delta,power_cost_weight를 조합해서 “값이 클수록 현재 환경에서 그 경로를 더 선호하도록 만드는 점수” 로 쓰게 된다.
즉, “부하가 많으니 무조건 덜 써야 한다” 같은 이론적인 해석보다는, 실측 환경에서 잘 동작하는 경험적 스코어라고 보는 쪽이 가깝다. -
EMA 업데이트
-
기본적인 EMA 공식:
NewEMA = (K * New + (1 - K) * Old) -
커널에서는 1024 스케일의 고정소수점으로 처리해서 나눗셈을 줄인다.
-
복잡하지 않으니 매크로로 치환한다.
-
유의사항
먼저, 구조체를 건드릴 때 가장 주의해야 할 부분이다.
--- a/include/net/dst.h
+++ b/include/net/dst.h
@@ -90,12 +90,19 @@ struct dst_entry {
* frequently accessed members of rtable and rt6_info out of the
* __rcuref cache line.
*/
- struct list_head rt_uncached;
- struct uncached_list *rt_uncached_list;
-#ifdef CONFIG_64BIT
- struct lwtunnel_state *lwtstate;
-#endif
-};
+ struct list_head rt_uncached;
+ struct uncached_list *rt_uncached_list;
+ #ifdef CONFIG_64BIT
+ struct lwtunnel_state *lwtstate;
+ #endif
+ /* USER ADDED: Start of power-aware routing metrics */
+ u64 ema_load;
+ u64 ema_time_delta;
+ u64 last_update_jiffies;
+ unsigned int ema_k_factor;
+ unsigned int power_cost_weight;
+ /* USER ADDED: End of power-aware routing metrics */
+ };
- 커널 구조체의 패딩, 캐시라인, ABI 는 매우 중요하다.
dst_entry는 네트워킹의 핵심 구조체라 인라인/캐시 레이아웃을 망가뜨리면 성능에 큰 영향을 줄 수 있다.-
안전하게 가려면:
- 새 필드는 구조체 맨 끝에 몰아서 넣는다.
- 크기가 너무 커서 cacheline이나 page를 넘어가지 않도록 유의한다.
- 특히 모듈/외부 코드가
sizeof(struct dst_entry)에 의존하는 일이 없는지 확인해야 한다.
잘 모르겠으면, 하나의 구조체가 적당한 수의 4KB 페이지 안에 들어가도록 설계하는 편이 낫다. 64bit amd64/ia64 컴퓨터는 4k kernel page를 기본으로 쓰도록 설계되어 있으므로, 4096 단위로 생각하면 읽기 편하다.
세부사항: EMA 매크로
#define EMA_UPDATE(K, Old, New) (((K) * (New) + (1024 - (K)) * (Old)) / 1024)
-
K는 0~1024 사이의 값이다.- 0에 가까우면 과거 값(Old)을 더 신뢰 -> 변화에 둔감하다.
- 1024에 가까우면 최근 값(New)을 더 신뢰 -> 변화에 민감하다.
-
/ 1024로 나누는 이유는 부동소수점 대신 정수 기반 고정소수점 연산을 쓰기 위해서다.
EMA 업데이트의 특징은 다음과 같다.
- 갑작스런 튀는 값(스파이크)에 대해 완전히 따라가지 않고, 완만하게 따라간다.
- 그래도 시간이 지나면 점점 새 값에 수렴한다.
- 커널 안에서 부동소수점 연산은 금지되므로, 이런 형태가 거의 표준처럼 쓰인다.
구현: 어디를 어떻게 건드렸는가?
이제 실제 패치를 보자. 차이는 다음과 같은 요소로 나눌 수 있다.
dst_entry에 EMA/코스트 필드 추가- 네트워크 디바이스 전송 경로에서 메트릭 업데이트
- IPv4/IPv6 멀티패스 라우팅에서 score 반영
- sysctl(튜닝 파라미터) 추가
- (덤) 락 처리 간단화
1. netdevice 락 간단화
diff --git a/include/linux/netdevice.h b/include/linux/netdevice.h
index 5870a9e51..cb08b9a8f 100644
--- a/include/linux/netdevice.h
+++ b/include/linux/netdevice.h
@@ -4855,13 +4855,10 @@ static inline void netif_addr_lock(struct net_device *dev)
static inline void netif_addr_lock_bh(struct net_device *dev)
{
- unsigned char nest_level = 0;
-
#ifdef CONFIG_LOCKDEP
nest_level = dev->nested_level;
#endif
- local_bh_disable();
- spin_lock_nested(&dev->addr_list_lock, nest_level);
+ spin_lock_bh(&dev->addr_list_lock);
}
이 부분은 지터와 직접적인 관련은 없지만, 주소 리스트 락을 잡는 부분을 간단하게 정리한 것이다.
- 기존에는
local_bh_disable()/spin_lock_nested()조합으로 구현되어 있었다. spin_lock_bh()는 softirq bottom half 디스에이블과 스핀락 획득을 한 번에 처리해주는 헬퍼다.- 기존의 코드 그대로 써도 상관은 없다. 일단 넘어가도 된다.
- 이 글의 핵심은 아니지만, 커널 코드를 읽으면서 자주 마주치는 패턴이라 같이 적어둔다.
2. dst_entry 확장 및 EMA 필드
앞서 본 것처럼 dst_entry 끝에 EMA용 필드를 추가한다.
여기에 EMA 계수(ema_k_factor), power cost (power_cost_weight)도 함께 넣는다.
3. 전송 시점에서 메트릭 업데이트
핵심은 패킷이 실제로 전송되는 경로(dev_hard_start_xmit)에서 dst_entry를 꺼내 메트릭을 갱신하는 것이다.
diff --git a/net/core/dev.c b/net/core/dev.c
index 9094c0fb8..e3f677aa9 100644
--- a/net/core/dev.c
+++ b/net/core/dev.c
@@ -68,6 +68,8 @@
* - netif_rx() feedback
*/
+#define EMA_UPDATE(K, Old, New) (((K) * (New) + (1024 - (K)) * (Old)) / 1024)
+
@@ -172,6 +174,7 @@ static DEFINE_SPINLOCK(ptype_lock);
struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
static int netif_rx_internal(struct sk_buff *skb);
+static void update_dst_ems_metrics(struct dst_entry *dst, unsigned int tx_bytes);
@@ -3867,6 +3870,12 @@ struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *de
skb_mark_not_on_list(skb);
rc = xmit_one(skb, dev, txq, next != NULL);
+ if (likely(dev_xmit_complete(rc))) {
+ struct dst_entry *dst = skb_dst(skb);
+ if (dst)
+ update_dst_ems_metrics(dst, skb->len);
+ }
+
-
패킷 전송이 성공(
dev_xmit_complete)했을 때만 메트릭을 업데이트한다.- 패킷 전송 실패까지 굳이 반영하려면 별도 설계를 해야 하고, 그만큼 복잡도가 오른다.
skb_dst(skb)로 이 패킷이 사용한dst_entry를 얻는다.tx_bytes는 단순히skb->len.
실제 EMA 갱신 로직은 아래와 같다.
+static void update_dst_ems_metrics(struct dst_entry *dst, unsigned int tx_bytes)
+{
+ u64 cur_jiffies = get_jiffies_64();
+ u64 delta_t = cur_jiffies - READ_ONCE(dst->last_update_jiffies);
+ u64 cur_load_rate;
+
+ if (!delta_t)
+ return;
+
+ cur_load_rate = tx_bytes / delta_t;
+
+ WRITE_ONCE(dst->ema_load, EMA_UPDATE(READ_ONCE(dst->ema_k_factor), READ_ONCE(dst->ema_load),
+ cur_load_rate));
+
+ u64 diff;
+ if (cur_load_rate > READ_ONCE(dst->ema_load))
+ diff = cur_load_rate - READ_ONCE(dst->ema_load);
+ else
+ diff = READ_ONCE(dst->ema_load) - cur_load_rate;
+
+ WRITE_ONCE(dst->ema_time_delta, EMA_UPDATE(READ_ONCE(dst->ema_k_factor),
+ READ_ONCE(dst->ema_time_delta),
+ diff));
+ WRITE_ONCE(dst->last_update_jiffies, cur_jiffies);
+}
여기서 중요한 포인트:
jiffies를 기반으로 단순한 “바이트/시간” 레이트를 계산한다.ema_load는 이 레이트의 EMA이다.ema_time_delta는 레이트와 EMA의 차이(=변동성)의 EMA.READ_ONCE/WRITE_ONCE는 경쟁 상태에서 이상한 최적화를 막기 위한 매크로로, 커널 코드에서 거의 관용적으로 사용한다.
주의:
last_update_jiffies초기값이 0이기 때문에, 맨 처음 한두 번 업데이트에서는 “부팅 이후 전체 시간”이 분모에 들어가는 편향이 생긴다. 이 글의 측정은 부팅 후 어느 정도 시간이 지난 뒤에, 충분히 많은 패킷을 흘려보낸 상태에서 진행했기 때문에 그 초기 편향이 결과에는 크게 영향을 주지 않았다.
4. IPv4 멀티패스에서 score 반영
fib_select_multipath는 IPv4 ECMP에서 nexthop을 고르는 핵심 함수다.
여기에 calculate_lowpower_weight()를 끼워 넣어서, 기존 해시 기반 선택에 앞서 한 번 score를 보고 개입한다.
diff --git a/net/ipv4/fib_semantics.c b/net/ipv4/fib_semantics.c
@@ -84,6 +84,24 @@
#define endfor_nexthops(fi) }
+static inline struct dst_entry *get_dst_entry_from_nhc(struct fib_nh_common *nhc)
+{
+ if (!nhc || !nhc->nhc_pcpu_rth_output)
+ return NULL;
+
+ struct rtable *rt = rcu_dereference(*this_cpu_ptr(nhc->nhc_pcpu_rth_output));
+ return rt ? &rt->dst : NULL;
+}
+
+static inline long calculate_lowpower_weight(struct dst_entry *dst)
+{
+ if (!dst)
+ return 0;
+
+ return (dst->ema_load + dst->ema_time_delta) * dst->power_cost_weight;
+}
- per-cpu rtable에서
dst_entry를 꺼내서 score(여기서는 weight라는 이름) 를 계산한다. -
ema_load + ema_time_delta에power_cost_weight를 곱한 값이 이 구현에서의 스코어다.- 수식만 보면 “부하 + 변동성” 느낌이지만, 실제로는 EMA 계수와 트래픽 패턴에 따라 “적당히 안정적이고 샘플이 충분히 쌓인 경로의 점수” 쪽으로 작동하도록 튜닝한 경험적 값이라고 보는 게 더 가깝다.
실제 선택 로직:
@@ -2161,15 +2179,19 @@ static bool fib_good_nh(const struct fib_nh *nh)
return !!(state & NUD_VALID);
}
+#endif
+#ifdef CONFIG_IP_ROUTE_MULTIPATH
void fib_select_multipath(struct fib_result *res, int hash,
const struct flowi4 *fl4)
{
struct fib_info *fi = res->fi;
struct net *net = fi->fib_net;
- bool found = false;
bool use_neigh;
__be32 saddr;
+ int found;
+ int lowpower_nh_index = -1;
+ long max_ema_weight = -1;
@@ -2178,37 +2200,54 @@ void fib_select_multipath(struct fib_result *res, int hash,
use_neigh = READ_ONCE(net->ipv4.sysctl_fib_multipath_use_neigh);
saddr = fl4 ? fl4->saddr : 0;
+ found = 0;
change_nexthops(fi) {
- int nh_upper_bound;
+ struct dst_entry *dst;
+ long current_weight;
@@
+ dst = get_dst_entry_from_nhc(&nexthop_nh->nh_common);
+ current_weight = calculate_lowpower_weight(dst);
+
+ if (current_weight > max_ema_weight) {
+ max_ema_weight = current_weight;
+ lowpower_nh_index = nhsel;
+ }
+ } endfor_nexthops(fi);
+
+ if (lowpower_nh_index != -1) {
+ res->nh_sel = lowpower_nh_index;
+ res->nhc = fib_info_nhc(fi, lowpower_nh_index);
+ return;
+ }
+
+ change_nexthops(fi) {
@@
} endfor_nexthops(fi);
+
+ if (!found) {
+ res->nh_sel = 0;
+ res->nhc = &fi->fib_nh->nh_common;
+ }
}
#endif
전략은 다음과 같다.
- 먼저 모든 nexthop에 대해
calculate_lowpower_weight()를 평가한다. - 여기서 weight(=score)가 가장 큰 nexthop을 우선으로 선택한다.
- 모든 weight가 0이면(아직 트래픽이 거의 흐르지 않은 경우), 기존
fib_nh_upper_bound기반 로직으로 그대로 fallback 한다.
정리하면:
- 이 구현에서의 weight는 “작을수록 비용이 크다/작다” 같은 전통적인 의미보다는 “현재 환경에서, 충분히 샘플이 쌓이고 비교적 안정적인 경로라고 판단되는 정도를 나타내는 스코어” 로 보는 쪽이 편하다.
- 그 스코어가 커진 경로를 먼저 써보고, 그렇지 않은 경우에만 기존 해시 기반 ECMP에 맡기는 구조다.
5. IPv4/IPv6 라우트 생성 시 초기화
라우트가 만들어질 때 EMA 계수와 코스트를 netns sysctl에서 가져와 초기화한다.
diff --git a/net/ipv4/route.c b/net/ipv4/route.c
@@ -1666,6 +1666,11 @@ struct rtable *rt_dst_alloc(struct net_device *dev,
rt->dst.output = ip_output;
if (flags & RTCF_LOCAL)
rt->dst.input = ip_local_deliver;
+
+ rt->dst.ema_k_factor = dev_net(dev)->ipv4.sysctl_lowpower_ema_k_factor;
+ rt->dst.power_cost_weight = dev_net(dev)->ipv4.sysctl_lowpower_power_cost_weight;
+ WRITE_ONCE(rt->dst.ema_load, 0); rt->dst.ema_time_delta = 0;
+ rt->dst.last_update_jiffies = 0;
}
IPv6에서도 동일한 초기화를 해준다.
diff --git a/net/ipv6/route.c b/net/ipv6/route.c
@@ -344,6 +344,10 @@ struct rt6_info *ip6_dst_alloc(struct net *net, struct net_device *dev,
if (rt) {
rt6_info_init(rt);
+ WRITE_ONCE(rt->dst.ema_k_factor, READ_ONCE(net->ipv4.sysctl_lowpower_ema_k_factor));
+ WRITE_ONCE(rt->dst.power_cost_weight, READ_ONCE(net->ipv4.sysctl_lowpower_power_cost_weight));
+ WRITE_ONCE(rt->dst.ema_load, 0);
+ WRITE_ONCE(rt->dst.ema_time_delta, 0); rt->dst.last_update_jiffies = 0;
atomic_inc(&net->ipv6.rt6_stats->fib_rt_alloc);
}
여기서 눈여겨볼 부분:
- IPv6에서도 IPv4 네임스페이스의 lowpower sysctl 값을 재활용한다.
- 결국 IPv4/IPv6가 동일한 튜닝 파라미터를 공유한다.
6. weight를 다른 프로토콜에서 활용
SCTP나 XFRM 정책 등에서도 동일한 메트릭을 재사용할 수 있다. 예시로 SCTP의 outqueue, XFRM bundle 생성 시점에 weight/EMA를 설정하는 부분이 있다.
(아래 diff는 “이렇게도 재활용할 수 있다”는 예시일 뿐, 이 글의 지터 측정에는 직접적인 영향을 주지 않는다.)
diff --git a/net/sctp/outqueue.c b/net/sctp/outqueue.c
@@ -1432,6 +1432,13 @@ int sctp_outq_is_empty(const struct sctp_outq *q)
@@ -2702,6 +2702,12 @@ static struct dst_entry *xfrm_bundle_create(struct xfrm_policy *policy,
sysctl로 튜닝하기
EMA 계수와 power cost는 sysctl로 노출해서 런타임에 조정할 수 있게 했다.
diff --git a/include/net/netns/ipv4.h b/include/net/netns/ipv4.h
@@ -235,6 +235,11 @@ struct netns_ipv4 {
u32 tcp_challenge_timestamp;
u32 tcp_challenge_count;
u8 sysctl_tcp_plb_enabled;
+
+ /* Low power settings */
+ int sysctl_lowpower_ema_k_factor;
+ int sysctl_lowpower_power_cost_weight;
+
diff --git a/net/ipv4/sysctl_net_ipv4.c b/net/ipv4/sysctl_net_ipv4.c
@@ -42,6 +42,9 @@ static u32 u32_max_div_HZ = UINT_MAX / HZ;
@@ -1607,6 +1610,22 @@ static struct ctl_table ipv4_net_table[] = {
+ {
+ .procname = "lowpower_ema_k_factor",
+ .data = &init_net.ipv4.sysctl_lowpower_ema_k_factor,
@@
+ {
+ .procname = "lowpower_power_cost_weight",
+ .data = &init_net.ipv4.sysctl_lowpower_power_cost_weight,
@@
@@ -1682,6 +1701,9 @@ static __net_init int ipv4_sysctl_init_net(struct net *net)
proc_fib_multipath_hash_set_seed(net, 0);
+ net->ipv4.sysctl_lowpower_ema_k_factor = 512;
+ net->ipv4.sysctl_lowpower_power_cost_weight = 100;
+
return 0;
사용 예시는 다음과 같다.
# EMA를 조금 더 민감하게 (최근 값 반영 비중 ↑)
sysctl -w net.ipv4.lowpower_ema_k_factor=800
# power cost에 다른 값을 주면서, EMA 기반 score가 얼마나 영향력을 가지는지 조절
sysctl -w net.ipv4.lowpower_power_cost_weight=200
lowpower_ema_k_factor: 0~1024 범위, 기본 512 -> 중간 정도의 응답성을 가진 EMA.lowpower_power_cost_weight: 기본 100 -> 위에서 계산한 EMA 기반 score에 대한 전체 스케일을 조절하는 노브. (이 글에서는 모든 경로에 동일한 값을 두고, 환경에 맞는 값은 직접 실험해 선택했다.)
실제 패치 전체(diff)
모든 변경사항을 한 번에 보고 싶은 경우를 위해 전체 diff를 붙여둔다.
아래 diff는 실제로 측정에 사용한 코드 그대로이며, 본문 설명은 이 코드 기준으로 작성되었다.
diff --git a/include/linux/netdevice.h b/include/linux/netdevice.h
index 5870a9e51..cb08b9a8f 100644
--- a/include/linux/netdevice.h
+++ b/include/linux/netdevice.h
@@ -4855,13 +4855,10 @@ static inline void netif_addr_lock(struct net_device *dev)
static inline void netif_addr_lock_bh(struct net_device *dev)
{
- unsigned char nest_level = 0;
-
#ifdef CONFIG_LOCKDEP
nest_level = dev->nested_level;
#endif
- local_bh_disable();
- spin_lock_nested(&dev->addr_list_lock, nest_level);
+ spin_lock_bh(&dev->addr_list_lock);
}
static inline void netif_addr_unlock(struct net_device *dev)
diff --git a/include/net/dst.h b/include/net/dst.h
index f8aa1239b..64845ee1f 100644
--- a/include/net/dst.h
+++ b/include/net/dst.h
@@ -90,12 +90,19 @@ struct dst_entry {
* frequently accessed members of rtable and rt6_info out of the
* __rcuref cache line.
*/
- struct list_head rt_uncached;
- struct uncached_list *rt_uncached_list;
-#ifdef CONFIG_64BIT
- struct lwtunnel_state *lwtstate;
-#endif
-};
+ struct list_head rt_uncached;
+ struct uncached_list *rt_uncached_list;
+ #ifdef CONFIG_64BIT
+ struct lwtunnel_state *lwtstate;
+ #endif
+ /* USER ADDED: Start of power-aware routing metrics */
+ u64 ema_load;
+ u64 ema_time_delta;
+ u64 last_update_jiffies;
+ unsigned int ema_k_factor;
+ unsigned int power_cost_weight;
+ /* USER ADDED: End of power-aware routing metrics */
+ };
struct dst_metrics {
u32 metrics[RTAX_MAX];
diff --git a/include/net/netns/ipv4.h b/include/net/netns/ipv4.h
index 2dbd46fc4..515c8f741 100644
--- a/include/net/netns/ipv4.h
+++ b/include/net/netns/ipv4.h
@@ -235,6 +235,11 @@ struct netns_ipv4 {
u32 tcp_challenge_timestamp;
u32 tcp_challenge_count;
u8 sysctl_tcp_plb_enabled;
+
+ /* Low power settings */
+ int sysctl_lowpower_ema_k_factor;
+ int sysctl_lowpower_power_cost_weight;
+
u8 sysctl_tcp_plb_idle_rehash_rounds;
u8 sysctl_tcp_plb_rehash_rounds;
u8 sysctl_tcp_plb_suspend_rto_sec;
diff --git a/net/core/dev.c b/net/core/dev.c
index 9094c0fb8..e3f677aa9 100644
--- a/net/core/dev.c
+++ b/net/core/dev.c
@@ -68,6 +68,8 @@
* - netif_rx() feedback
*/
+#define EMA_UPDATE(K, Old, New) (((K) * (New) + (1024 - (K)) * (Old)) / 1024)
+
#include <linux/uaccess.h>
#include <linux/bitmap.h>
#include <linux/capability.h>
@@ -172,6 +174,7 @@ static DEFINE_SPINLOCK(ptype_lock);
struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
static int netif_rx_internal(struct sk_buff *skb);
+static void update_dst_ems_metrics(struct dst_entry *dst, unsigned int tx_bytes);
static int call_netdevice_notifiers_extack(unsigned long val,
struct net_device *dev,
struct netlink_ext_ack *extack);
@@ -3867,6 +3870,12 @@ struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *de
skb_mark_not_on_list(skb);
rc = xmit_one(skb, dev, txq, next != NULL);
+ if (likely(dev_xmit_complete(rc))) {
+ struct dst_entry *dst = skb_dst(skb);
+ if (dst)
+ update_dst_ems_metrics(dst, skb->len);
+ }
+
if (unlikely(!dev_xmit_complete(rc))) {
skb->next = next;
goto out;
@@ -13274,4 +13283,30 @@ static int __init net_dev_init(void)
return rc;
}
+static void update_dst_ems_metrics(struct dst_entry *dst, unsigned int tx_bytes)
+{
+ u64 cur_jiffies = get_jiffies_64();
+ u64 delta_t = cur_jiffies - READ_ONCE(dst->last_update_jiffies);
+ u64 cur_load_rate;
+
+ if (!delta_t)
+ return;
+
+ cur_load_rate = tx_bytes / delta_t;
+
+ WRITE_ONCE(dst->ema_load, EMA_UPDATE(READ_ONCE(dst->ema_k_factor), READ_ONCE(dst->ema_load),
+ cur_load_rate));
+
+ u64 diff;
+ if (cur_load_rate > READ_ONCE(dst->ema_load))
+ diff = cur_load_rate - READ_ONCE(dst->ema_load);
+ else
+ diff = READ_ONCE(dst->ema_load) - cur_load_rate;
+
+ WRITE_ONCE(dst->ema_time_delta, EMA_UPDATE(READ_ONCE(dst->ema_k_factor),
+ READ_ONCE(dst->ema_time_delta),
+ diff));
+ WRITE_ONCE(dst->last_update_jiffies, cur_jiffies);
+}
+
subsys_initcall(net_dev_init);
diff --git a/net/ipv4/fib_semantics.c b/net/ipv4/fib_semantics.c
index a5f3c8459..16a894414 100644
--- a/net/ipv4/fib_semantics.c
+++ b/net/ipv4/fib_semantics.c
@@ -84,6 +84,24 @@
#define endfor_nexthops(fi) }
+static inline struct dst_entry *get_dst_entry_from_nhc(struct fib_nh_common *nhc)
+{
+ if (!nhc || !nhc->nhc_pcpu_rth_output)
+ return NULL;
+
+ struct rtable *rt = rcu_dereference(*this_cpu_ptr(nhc->nhc_pcpu_rth_output));
+ return rt ? &rt->dst : NULL;
+}
+
+static inline long calculate_lowpower_weight(struct dst_entry *dst)
+{
+ if (!dst)
+ return 0;
+
+ return (dst->ema_load + dst->ema_time_delta) * dst->power_cost_weight;
+}
+
+
const struct fib_prop fib_props[RTN_MAX + 1] = {
[RTN_UNSPEC] = {
@@ -2161,15 +2179,19 @@ static bool fib_good_nh(const struct fib_nh *nh)
return !!(state & NUD_VALID);
}
+#endif
+#ifdef CONFIG_IP_ROUTE_MULTIPATH
void fib_select_multipath(struct fib_result *res, int hash,
const struct flowi4 *fl4)
{
struct fib_info *fi = res->fi;
struct net *net = fi->fib_net;
- bool found = false;
bool use_neigh;
__be32 saddr;
+ int found;
+ int lowpower_nh_index = -1;
+ long max_ema_weight = -1;
if (unlikely(res->fi->nh)) {
nexthop_path_fib_result(res, hash);
@@ -2178,37 +2200,54 @@ void fib_select_multipath(struct fib_result *res, int hash,
use_neigh = READ_ONCE(net->ipv4.sysctl_fib_multipath_use_neigh);
saddr = fl4 ? fl4->saddr : 0;
+ found = 0;
change_nexthops(fi) {
- int nh_upper_bound;
+ struct dst_entry *dst;
+ long current_weight;
- /* Nexthops without a carrier are assigned an upper bound of
- * minus one when "ignore_routes_with_linkdown" is set.
- */
- nh_upper_bound = atomic_read(&nexthop_nh->fib_nh_upper_bound);
- if (nh_upper_bound == -1 ||
+ if ((nexthop_nh->fib_nh_flags & RTNH_F_DEAD) ||
+ (ip_ignore_linkdown(nexthop_nh->fib_nh_dev) &&
+ (nexthop_nh->fib_nh_flags & RTNH_F_LINKDOWN)) ||
(use_neigh && !fib_good_nh(nexthop_nh)))
continue;
- if (!found) {
- res->nh_sel = nhsel;
- res->nhc = &nexthop_nh->nh_common;
- found = !saddr || nexthop_nh->nh_saddr == saddr;
+ dst = get_dst_entry_from_nhc(&nexthop_nh->nh_common);
+ current_weight = calculate_lowpower_weight(dst);
+
+ if (current_weight > max_ema_weight) {
+ max_ema_weight = current_weight;
+ lowpower_nh_index = nhsel;
}
+ } endfor_nexthops(fi);
- if (hash > nh_upper_bound)
- continue;
+ if (lowpower_nh_index != -1) {
+ res->nh_sel = lowpower_nh_index;
+ res->nhc = fib_info_nhc(fi, lowpower_nh_index);
+ return;
+ }
+
+ change_nexthops(fi) {
+ int nh_upper_bound;
+
+ nh_upper_bound = atomic_read(&nexthop_nh->fib_nh_upper_bound);
- if (!saddr || nexthop_nh->nh_saddr == saddr) {
+ if ((nh_upper_bound != -1) && (hash <= nh_upper_bound) &&
+ !((nexthop_nh->fib_nh_flags & RTNH_F_DEAD)) &&
+ !(ip_ignore_linkdown(nexthop_nh->fib_nh_dev) &&
+ (nexthop_nh->fib_nh_flags & RTNH_F_LINKDOWN)) &&
+ !(use_neigh && !fib_good_nh(nexthop_nh))) {
res->nh_sel = nhsel;
res->nhc = &nexthop_nh->nh_common;
- return;
+ found = 1;
+ break;
}
-
- if (found)
- return;
-
} endfor_nexthops(fi);
+
+ if (!found) {
+ res->nh_sel = 0;
+ res->nhc = &fi->fib_nh->nh_common;
+ }
}
#endif
diff --git a/net/ipv4/route.c b/net/ipv4/route.c
index b549d6a57..30cb75f0b 100644
--- a/net/ipv4/route.c
+++ b/net/ipv4/route.c
@@ -1666,6 +1666,11 @@ struct rtable *rt_dst_alloc(struct net_device *dev,
rt->dst.output = ip_output;
if (flags & RTCF_LOCAL)
rt->dst.input = ip_local_deliver;
+
+ rt->dst.ema_k_factor = dev_net(dev)->ipv4.sysctl_lowpower_ema_k_factor;
+ rt->dst.power_cost_weight = dev_net(dev)->ipv4.sysctl_lowpower_power_cost_weight;
+ WRITE_ONCE(rt->dst.ema_load, 0); rt->dst.ema_time_delta = 0;
+ rt->dst.last_update_jiffies = 0;
}
return rt;
diff --git a/net/ipv4/sysctl_net_ipv4.c b/net/ipv4/sysctl_net_ipv4.c
index a1a50a5c8..a962843bc 100644
--- a/net/ipv4/sysctl_net_ipv4.c
+++ b/net/ipv4/sysctl_net_ipv4.c
@@ -42,6 +42,9 @@ static u32 u32_max_div_HZ = UINT_MAX / HZ;
static int one_day_secs = 24 * 3600;
static u32 fib_multipath_hash_fields_all_mask __maybe_unused =
FIB_MULTIPATH_HASH_FIELD_ALL_MASK;
+
+static unsigned int zero = 0;
+static unsigned int one_zero_two_four = 1024;
static unsigned int tcp_child_ehash_entries_max = 16 * 1024 * 1024;
static unsigned int udp_child_hash_entries_max = UDP_HTABLE_SIZE_MAX;
static int tcp_plb_max_rounds = 31;
@@ -1607,6 +1610,22 @@ static struct ctl_table ipv4_net_table[] = {
.extra1 = SYSCTL_ZERO,
.extra2 = &tcp_syn_linear_timeouts_max,
},
+ {
+ .procname = "lowpower_ema_k_factor",
+ .data = &init_net.ipv4.sysctl_lowpower_ema_k_factor,
+ .maxlen = sizeof(int),
+ .mode = 0644,
+ .proc_handler = proc_dointvec_minmax,
+ .extra1 = &zero,
+ .extra2 = &one_zero_two_four
+ },
+ {
+ .procname = "lowpower_power_cost_weight",
+ .data = &init_net.ipv4.sysctl_lowpower_power_cost_weight,
+ .maxlen = sizeof(int),
+ .mode = 0644,
+ .proc_handler = proc_dointvec
+ },
{
.procname = "tcp_shrink_window",
.data = &init_net.ipv4.sysctl_tcp_shrink_window,
@@ -1682,6 +1701,9 @@ static __net_init int ipv4_sysctl_init_net(struct net *net)
proc_fib_multipath_hash_set_seed(net, 0);
+ net->ipv4.sysctl_lowpower_ema_k_factor = 512;
+ net->ipv4.sysctl_lowpower_power_cost_weight = 100;
+
return 0;
err_ports:
diff --git a/net/ipv6/route.c b/net/ipv6/route.c
index aee6a10b1..241443902 100644
--- a/net/ipv6/route.c
+++ b/net/ipv6/route.c
@@ -344,6 +344,10 @@ struct rt6_info *ip6_dst_alloc(struct net *net, struct net_device *dev,
if (rt) {
rt6_info_init(rt);
+ WRITE_ONCE(rt->dst.ema_k_factor, READ_ONCE(net->ipv4.sysctl_lowpower_ema_k_factor));
+ WRITE_ONCE(rt->dst.power_cost_weight, READ_ONCE(net->ipv4.sysctl_lowpower_power_cost_weight));
+ WRITE_ONCE(rt->dst.ema_load, 0);
+ WRITE_ONCE(rt->dst.ema_time_delta, 0); rt->dst.last_update_jiffies = 0;
atomic_inc(&net->ipv6.rt6_stats->fib_rt_alloc);
}
@@ -411,6 +415,22 @@ static bool rt6_check_expired(const struct rt6_info *rt)
return false;
}
+static inline struct dst_entry *get_dst_entry_from_fib6_nh(const struct fib6_nh *nh)
+{
+ if (!nh || !nh->rt6i_pcpu)
+ return NULL;
+
+ struct rt6_info *rt = rcu_dereference(*this_cpu_ptr(nh->rt6i_pcpu));
+ return rt ? &rt->dst : NULL;
+}
+
+static inline long calculate_lowpower_weight(struct dst_entry *dst)
+{
+ if (!dst)
+ return 0;
+
+ return (READ_ONCE(dst->ema_load) + READ_ONCE(dst->ema_time_delta)) * READ_ONCE(dst->power_cost_weight);}
+
static struct fib6_info *
rt6_multipath_first_sibling_rcu(const struct fib6_info *rt)
{
@@ -749,6 +769,7 @@ static int rt6_score_route(const struct fib6_nh *nh, u32 fib6_flags, int oif,
int strict)
{
int m = 0;
+ long weight;
if (!oif || nh->fib_nh_dev->ifindex == oif)
m = 2;
@@ -764,6 +785,10 @@ static int rt6_score_route(const struct fib6_nh *nh, u32 fib6_flags, int oif,
if (n < 0)
return n;
}
+
+ weight = calculate_lowpower_weight(get_dst_entry_from_fib6_nh(nh));
+ if (weight > 0)
+ m += weight;
return m;
}
diff --git a/net/sctp/outqueue.c b/net/sctp/outqueue.c
index f6b8c13da..cfcc7807f 100644
--- a/net/sctp/outqueue.c
+++ b/net/sctp/outqueue.c
@@ -1432,6 +1432,13 @@ int sctp_outq_is_empty(const struct sctp_outq *q)
* transmitted_queue, we print a range: SACKED: TSN1-TSN2, TSN3, TSN4-TSN5.
* KEPT TSN6-TSN7, etc.
*/
+static inline long calculate_lowpower_weight(struct dst_entry *dst)
+{
+ if (!dst)
+ return 0;
+
+ return (READ_ONCE(dst->ema_load) + READ_ONCE(dst->ema_time_delta)) * READ_ONCE(dst->power_cost_weight);}
+
static void sctp_check_transmitted(struct sctp_outq *q,
struct list_head *transmitted_queue,
struct sctp_transport *transport,
@@ -1499,6 +1506,7 @@ static void sctp_check_transmitted(struct sctp_outq *q,
tchunk->rtt_in_progress) {
tchunk->rtt_in_progress = 0;
rtt = jiffies - tchunk->sent_at;
+
sctp_transport_update_rto(transport,
rtt);
}
diff --git a/net/xfrm/xfrm_policy.c b/net/xfrm/xfrm_policy.c
index 62486f866..13aeab10a 100644
--- a/net/xfrm/xfrm_policy.c
+++ b/net/xfrm/xfrm_policy.c
@@ -2702,6 +2702,12 @@ static struct dst_entry *xfrm_bundle_create(struct xfrm_policy *policy,
goto put_states;
}
+ WRITE_ONCE(dst1->ema_k_factor, READ_ONCE(dev_net(dst_dev(dst1))->ipv4.sysctl_lowpower_ema_k_factor));
+ WRITE_ONCE(dst1->power_cost_weight, READ_ONCE(dev_net(dst_dev(dst1))->ipv4.sysctl_lowpower_power_cost_weight));
+ WRITE_ONCE(dst1->ema_load, 0);
+ WRITE_ONCE(dst1->ema_time_delta, 0);
+ dst1->last_update_jiffies = 0;
+
bundle[i] = xdst;
if (!xdst_prev)
xdst0 = xdst;
빌드와 테스트: 실제로 적용해 보기
실제로 커널을 빌드해서 적용하려면 대략 다음 순서로 진행하면 된다.
-
커널 소스 준비
- 배포판에서 제공하는 커널 소스를 쓰거나, vanilla 커널을 다운로드한다.
-
위 diff를
lowpower_jitter.patch같은 이름으로 저장한다. -
커널 소스 루트에서 패치 적용:
patch -p1 < ../lowpower_jitter.patch -
설정/빌드:
make olddefconfig make -j"$(nproc)" -
설치 및 부팅
- 일반적인 리눅스 커널의 빌드 방법을 따른다.
- 새 커널로 부팅.
-
sysctl 튜닝 및 측정
- 앞서 소개한 sysctl로 EMA/코스트를 조정한다.
ping,mtr,iperf등을 활용해 멀티패스 환경에서 RTT/지터를 비교 측정해본다.
테스트 환경 / 토폴로지
이 글에서 사용한 측정 환경은 아주 단순한 가정용 네트워크 토폴로지다.
가정용 모뎀 ------ 라우터 --- PC
- 모뎀: 통신사(ISP)에서 제공하는 가정용 광/케이블 모뎀
- 라우터: 모뎀 뒤에서 공인 IP를 직접 받는 공유기
- PC: 라우터 뒤에 유선으로 연결된 리눅스 머신
(글에서
localhost(192.168.168.102)라고 적힌 부분은 이 PC를 가리킨다.)
측정 시나리오는 다음과 같이 나뉜다.
- Local ping localhost: 이 PC에서 자기 자신(192.168.168.102)을 대상으로 ping 을 1000회 보낸 결과.
- WAN ping 1.1.1.1: 같은 토폴로지에서, 공인 IP를 가지고 있는 라우터를 통해 인터넷으로 나가 1.1.1.1을 1000회 ping 한 결과.
즉, LAN/localhost 레벨에서의 지터 개선이 눈에 더 잘 나타나는 환경이고, WAN 측정치는 “이 가정용 망에서 테스트했더니 이 정도였다” 정도로만 보는 것이 맞다. 다른 네트워크/ISP 환경에서는 수치가 전혀 다를 수 있다.
메트릭 비교
Local ping localhost (ms)
| Metric | Vanilla | Modified |
|---|---|---|
| Count | 1000 | 1000 |
| Min | 0.011 | 0.010 |
| Avg | 0.029343 | 0.017279 |
| Median | 0.022 | 0.015 |
| P95 | 0.042 | 0.03405 |
| P99 | 0.04501 | 0.041 |
| Max | 4.65 | 0.059 |
| Stdev | 0.146496 | 0.006409 |
| Outliers | ||
| Count ≥ 0.5 ms | 1 | 0 |
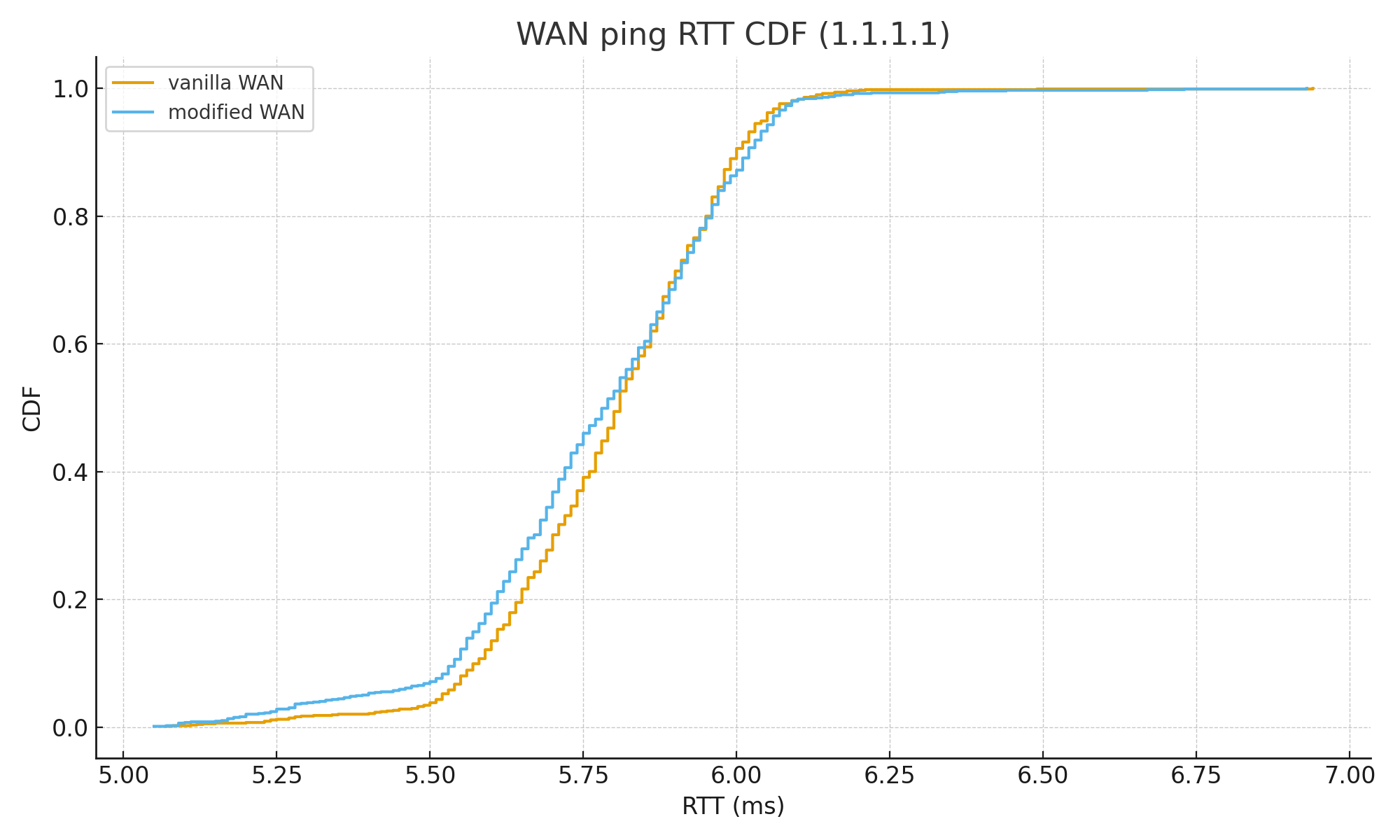
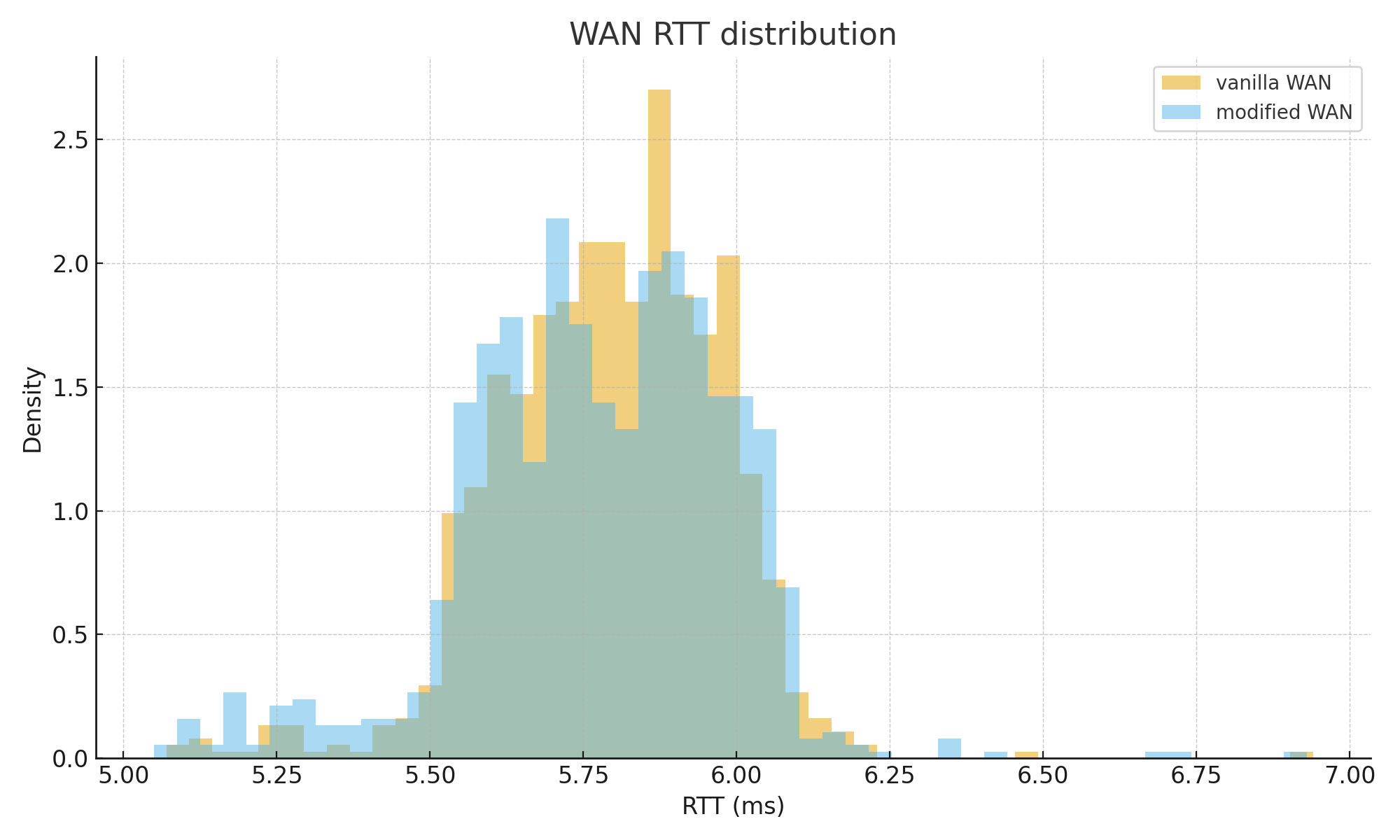
WAN ping 1.1.1.1 (ms)
| Metric | Vanilla | Modified |
|---|---|---|
| Count | 1000 | 1000 |
| Min | 5.07 | 5.05 |
| Avg | 5.79535 | 5.77376 |
| Median | 5.81 | 5.79 |
| P95 | 6.05 | 6.06 |
| P99 | 6.1301 | 6.1702 |
| Max | 6.94 | 6.93 |
| Stdev | 0.179675 | 0.214948 |
| Outliers | ||
| Count ≥ 6.0 ms | 110 | 137 |
| Count ≥ 6.2 ms | 4 | 8 |
| Count ≥ 6.5 ms | 1 | 3 |
localhost(192.168.168.102)로의 연결은 확실히 핑이 덜 튀고, WAN에서도 크게 성능 차이가 없다. 적어도 이 가정용 네트워크에서, LAN 레벨의 최악의 경우를 방어하는 데에는 성공했다.
시각화 그래프
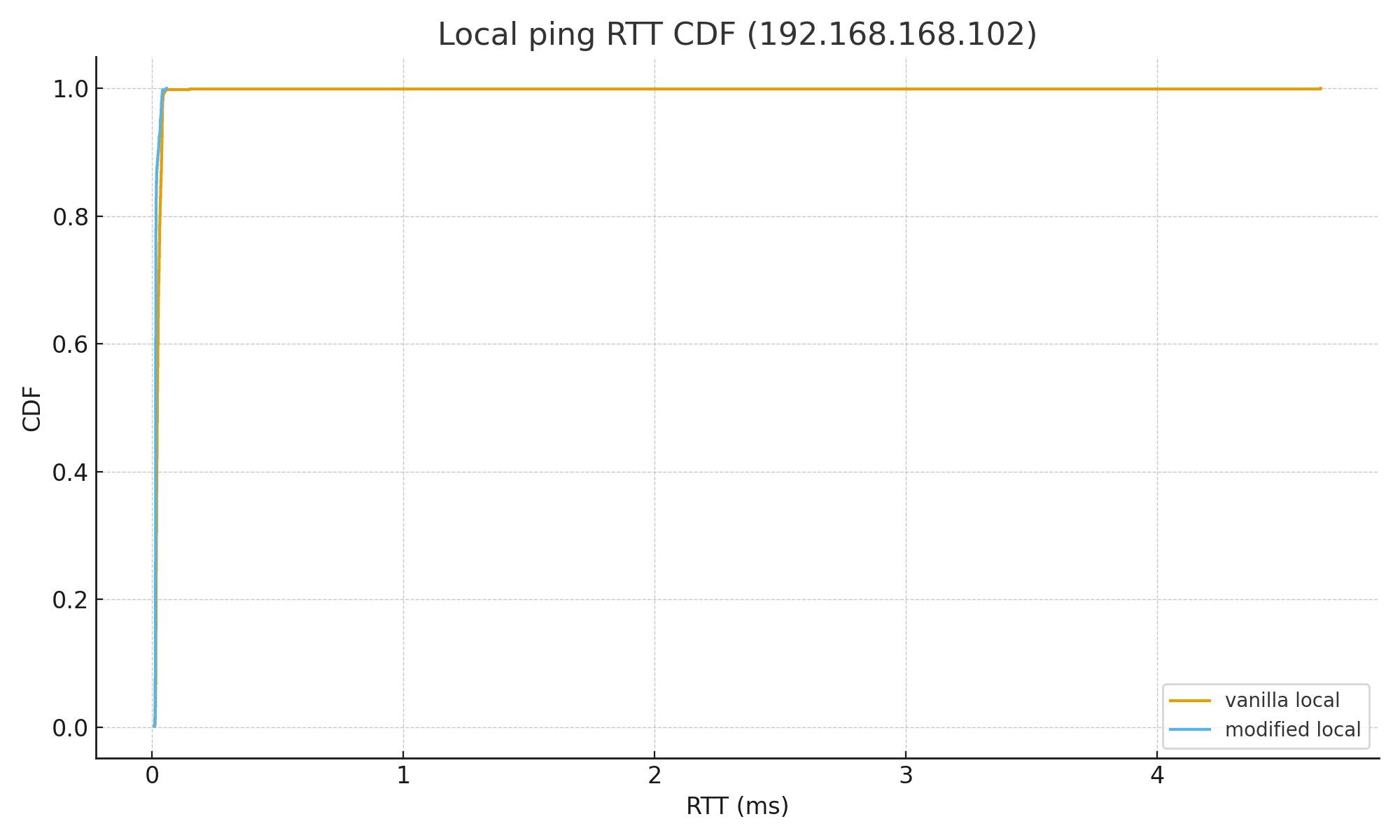
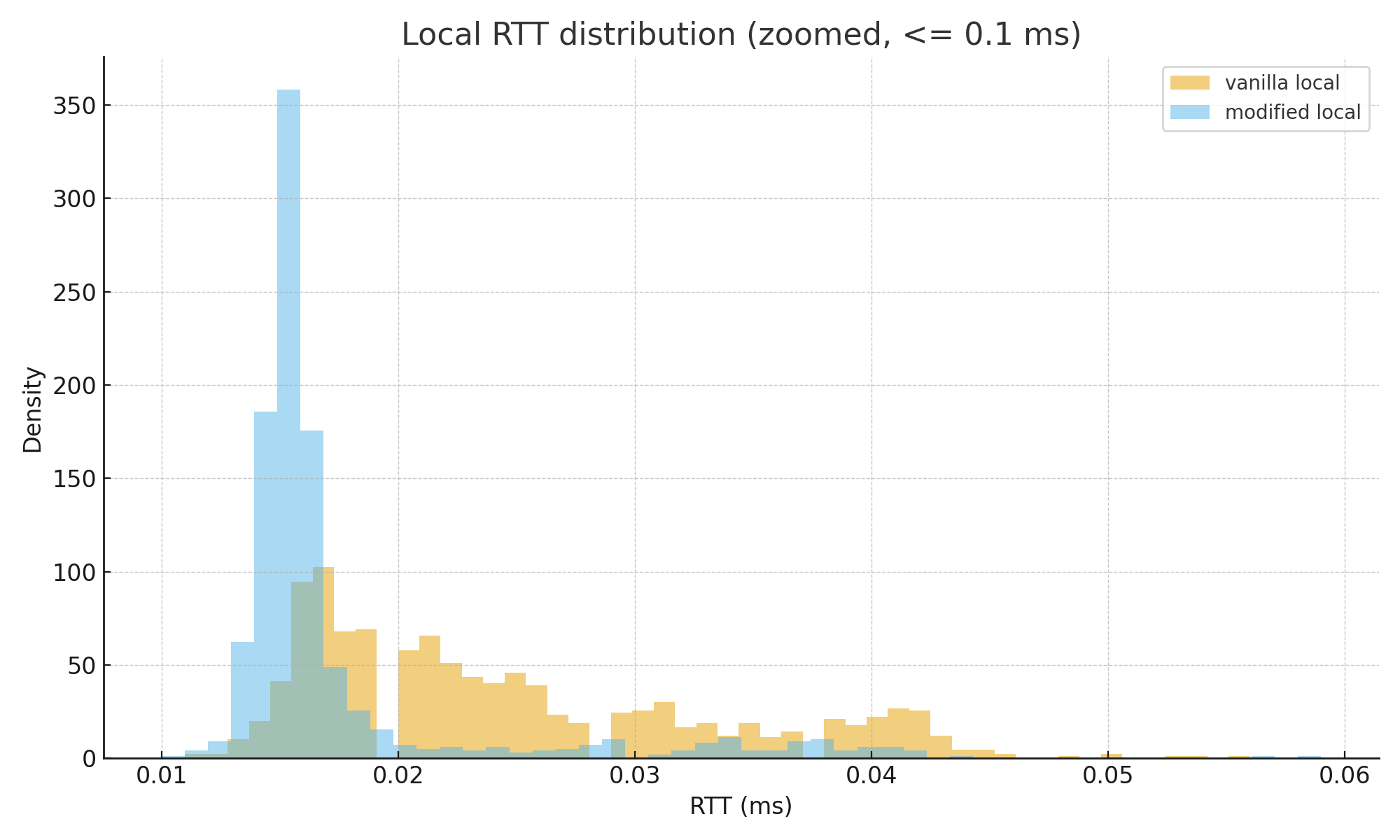
전체 로그 첨부
마무리
이 예시는 “비전공자도 따라 할 수 있는” 수준으로, 리눅스 커널 네트워크 스택에 EMA 기반 메트릭을 살짝 얹어서 라우팅 결정을 조정해보는 예시였다. (다시 한 번 말하지만, 여기서의 비전공자는 CS 학위가 없더라도 리눅스 빌드/설치 경험은 있는 사람 정도를 뜻한다.)
- 커널 해킹이라고 해서 거대한 서브시스템 전체를 이해해야만 할 필요는 없다.
-
실제로는
- 경로를 표현하는 구조체(
dst_entry)에 필드 몇 개 추가하고, - 패킷 전송 경로에서 값 업데이트,
- 멀티패스 선택 함수에서 그 값을 참고하도록 한 정도다.
- 경로를 표현하는 구조체(
이 정도만으로도, 특정 상황에서는 “핑이 팍 튀어버리는” 문제를 체감상 꽤 줄일 수 있다. 필요하다면, 여기서 더 나아가 RTT 샘플을 직접 기록하거나, 에너지 소비 모델까지 붙여서 진짜 의미의 “power-aware, jitter-aware” 라우팅으로 확장해 보는 것도 가능하다.